
카테고리 없음
데이터 분석 트랙 51일차 25.04.24. [TIL]
jjaio8986
2025. 4. 24. 21:09
[프로젝트 진행상황]
- 최종 데이터 전처리 후 가상 시나리오 그룹(초기 피쳐 설정) 별 군집 모델 생성 중
Group_A_재무건전성 (8개)
고객의 ‘재무 건전성’을 평가하는 변수 묶음
- 변수 목록
- per_capita_income (1인당 소득)
- yearly_income (연간 소득)
- total_debt (총 부채)
- DTI (Debt-to-Income ratio: 부채÷소득)
- credit_utilization (신용 한도 대비 사용률)
- card_per_income (소득 대비 카드 수)
- common_credit_score (100단위 신용점수 구간)
- num_credit_cards (보유 신용카드 수)
- 설명 & 기대 인사이트
- 부채 수준 vs. 소득: DTI, total_debt, yearly_income으로 재무 위험도 구분
- 한도 활용도: credit_utilization으로 과도 사용 고객 식별
- 카드 과소비 리스크: card_per_income, num_credit_cards
- 신용평점: common_credit_score로 신용등급별 분포 파악
Group_B_소비패턴 (8개)
실제 소비 행태를 보여주는 변수 묶음
- 변수 목록
- amount (총 거래 금액 또는 평균 거래액)
- trans_cnt (거래 건수)
- trans_stats (거래 변동성: 표준편차÷평균)
- high_amount_ratio (고액 결제 비율)
- monthly_insufficient_rate (월단위 잔액부족 비율)
- yearly_insufficient_rate (연단위 잔액부족 비율)
- night_ratio (야간 거래 비율)
- chip_use_ratio (칩 결제 비율)
- 설명 & 기대 인사이트
- 소비 규모 vs. 빈도: amount, trans_cnt
- 안정성 vs. 충동: trans_stats가 높으면 변동성이 큰 충동 소비자
- 리스크 행동: 잔액부족 비율(insufficient), 야간 거래 비율 등
- 결제 수단 선호: chip_use_ratio로 안전결제 선호도
Group_C_카드프로필 (7개)
고객의 카드 이용·관리 특성을 보여주는 변수 묶음
- 변수 목록
- ~~card_age (카드 보유 기간, 년 단위)~~
- account_age (계좌 개설 후 경과 기간)
- min_days_to_expire (만료일까지 남은 최소 일수)
- pin_age (PIN 마지막 변경 후 경과 년수)
- avg_cards_issued_per_year (연평균 발급 카드 수)
- num_cards_issued (총 발급 카드 수)
- credit_score (신용점수)
- 설명 & 기대 인사이트
- 신규 vs. 장기 고객: card_age, account_age
- 보안 민감도: pin_age로 PIN 변경 주기 파악
- 카드 관리 리스크: expires→min_days_to_expire
- 발급 성향: avg_cards_issued_per_year, num_cards_issued
Group_D_ 카드 사기 위험군 고객 세그멘테이션 (8개) - 지오 -
기본 인구·신용 통계를 합친 변수 묶음
- 변수 목록
- current_age (현재 나이)
- credut_utilization (신용카드 이용율)
- per_capita_income (1인당 소득)
- yearly_income (연소득)
- num_credit_cards (보유 카드 수)
- common_credit_score (100단위 신용 구간)
- 'pin_age' (핀번호 교체 주기)
- 'chip_use_ratio' (ic칩 카드 사용율)
- 'high_amount_ratio' (과소비 거래 비율)
- 설명 & 기대 인사이트
- 연령대별 리스크
- 소득·신용
- 카드 보안 정도
Group_E_재무건전성+ 소비패턴
- 재무건전성 & 소비패턴 결합 클러스터링을 통한 고객 리스크 세분화
- (고위험,고소비) 고객, (안정형,절약형)고객등 재무건전성 & 소비패턴 결합 클러스터링을 통한 고객 리스크 세분화
- A
- per_capita_income (1인당 소득)
- yearly_income (연간 소득)
- total_debt (총 부채)
- DTI (Debt-to-Income ratio: 부채÷소득)
- credit_utilization (신용 한도 대비 사용률)
- card_per_income (소득 대비 카드 수)
- common_credit_score (100단위 신용점수 구간)
- num_credit_cards (보유 신용카드 수)
- B
- amount (총 거래 금액 또는 평균 거래액)
- trans_cnt (거래 건수)
- trans_stats (거래 변동성: 표준편차÷평균)
- high_amount_ratio (고액 결제 비율)
- monthly_insufficient_rate (월단위 잔액부족 비율)
- yearly_insufficient_rate (연단위 잔액부족 비율)
- night_ratio (야간 거래 비율)
- chip_use_ratio (칩 결제 비율)
현재 개인 선택한 그룹의 클러스터링 예시
scale_df = df3[['chip_use_ratio', 'pin_age', 'use_chip', 'card_type', 'credit_utilization']]
설명 분산 비율 : 0.85463

Cluster count percentage
0 0 130 12.20
1 1 128 12.01
2 2 299 28.05
3 3 362 33.96
4 4 147 13.79
0 12.20
1 12.01
2 28.05
3 33.96
4 13.79
Name: percentage, dtype: float64
=== 군집 결과 비교 ===
[K-Means] Silhouette = 0.328730 , Davies-Bouldin = 0.824049
[DBSCAN] Silhouette = 0.521918 , Davies-Bouldin = 0.531495
[Agglomerative] Silhouette = 0.277461 , Davies-Bouldin = 0.779427
0 0 130 12.20
1 1 128 12.01
2 2 299 28.05
3 3 362 33.96
4 4 147 13.79
0 12.20
1 12.01
2 28.05
3 33.96
4 13.79
Name: percentage, dtype: float64
=== 군집 결과 비교 ===
[K-Means] Silhouette = 0.328730 , Davies-Bouldin = 0.824049
[DBSCAN] Silhouette = 0.521918 , Davies-Bouldin = 0.531495
[Agglomerative] Silhouette = 0.277461 , Davies-Bouldin = 0.779427
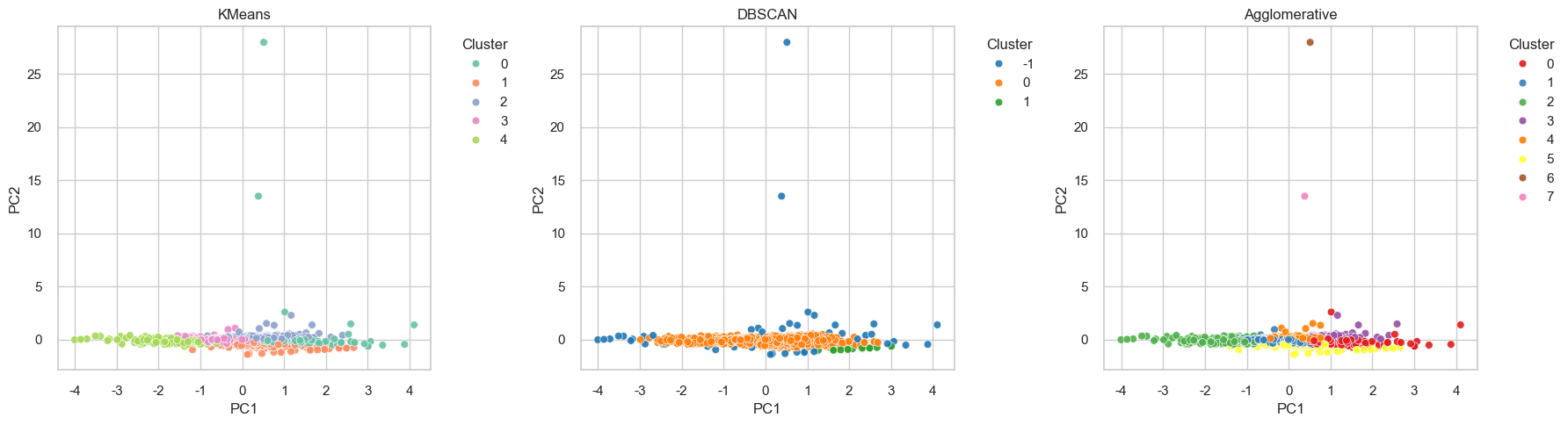
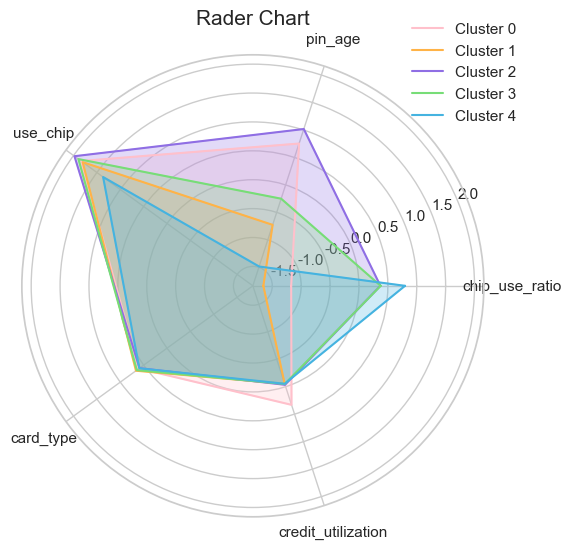
# 명확하게 구분되는 느낌이 없다. 아마 관련도가 높은 컬럼을 사용하여 PCA 그래프와 레이더차트가 유사한 그룹핑 특성을 갖는 것 같다.
# 레이더 차트만 볼 경우 각 클러스터별 해석을 유의미하게 할 수 있지만 같은 값이 나온 컬럼을 제외하고 다른 컬럼을 조합해볼 수 있을 것이다!
# 내일은 대부분 유사한 레이더 값을 가진 컬럼을 제외하고, 큰 차이를 가진 특성을 가져가 모델링을 시도한 뒤 해석을 해보아야 할 것 같다.